I sistemi OCR, sistemi di riconoscimento ottico dei caratteri, sono applicazioni che permettono di convertire immagini che contengono testo in testo digitale modificabile.
I sistemi OCR sono particolarmente utili quando di ha la necessità di estrarre il testo da un documento acquisito tramite scanner come immagine ma molto spesso vengono utilizzati con i file PDF.
Normalmente i PDF contengono testo che può essere selezionato, copiato e cercato. In alcuni casi i file PDF sono però scansioni di documenti e il testo mostrato è un’immagine.
In questi casi è utile convertire il contenuto in testo. e in questa guida segnaliamo i migliori programmi gratis e strumenti online disponibili in rete.
Per quanto riguarda la storia e la tecnica utilizzata per il riconoscimento dei caratteri rimandiamo invece a questo articolo in cui è presente un approfondimento piuttosto interessante sull’argomento.
Indice
Programmi o Servizi Online
La scelta dello strumento OCR giusto dipende dalle proprie necessità, una prima divisione può essere fatta tra programmi da installare sul computer e servizi online da utilizzare con il browser.
Le due soluzioni hanno vantaggi e svantaggi.
I servizi online richiedono l’upload dei propri file sul server che ospita il sito, questo può creare preoccupazioni per quanto riguarda la privacy, specie nel caso in cui il documento caricato contenga dati sensibili.
Da considerare poi che quasi tutti gli strumenti online gratis hanno limiti relativamente alla dimensione dei file e al numero di pagine per cui è possibile effettuare il riconoscimento OCR.
Il vantaggio è rappresentato dalla qualità, in rete troviamo strumenti che offrono ottime prestazioni e un’elaborazione precisa del testo estratto dalle immagini.
I programmi da installare sul computer eliminano le preoccupazioni che derivano dall’invio di dati sensibili tramite la rete e normalmente mettono a disposizione un numero maggiore di opzioni.
I programmi gratis disponibili non sono però molti e spesso hanno una qualità inferiore rispetto a quella offerta dai servizi online.
Per quanto riguarda le caratteristiche delle varie applicazioni, è importante sapere che, per migliorare il riconoscimento del testo, la maggioranza degli strumenti utilizza dei dizionari.
Invece che riconoscere i singoli caratteri, questi strumenti cercano di riconoscere le parole complete che esistono all’interno dei dizionari utilizzati.
Da segnalare è che alcuni servizi OCR non riescono a rilevare la formattazione, come risultato si ha quindi testo semplice, senza maiuscole o corsivo.
Altri sono invece più avanzati, possono anche individuare formattazione, colonne multiple e tabelle.
OCR Online
Per chi utilizza Gmail o un altro dei servizi Google, la prima soluzione è rappresentata da Google Drive
Non si tratta di uno strumento dedicato in modo esclusivo alla scansione OCR ma offre funzionalità molto interessanti.
Per estrarre il testo da un’immagine o da un PDF bisogna prima caricare e convertire il file su Google Drive, vediamo come fare.
Come prima cosa bisogna accedere a Google Drive con il proprio account Google, cliccare l’icona Impostazioni posizionata in alto a destra e selezionare Impostazioni caricamento – Converti testo da file di immagine o PDF caricati.
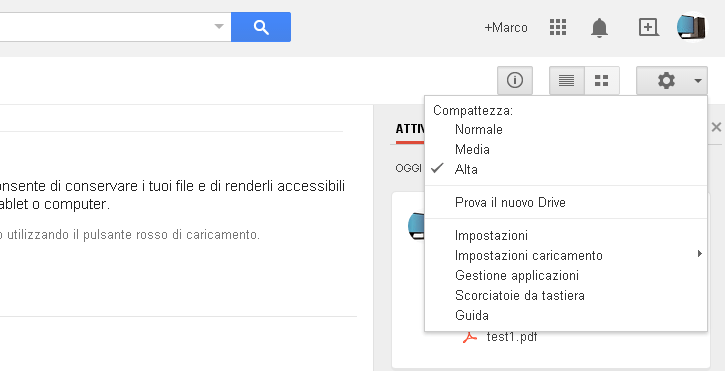 A questo punto è possibile cliccare il pulsante Carica, presente in alto a sinistra, e scegliere il file da importare dal proprio computer.
A questo punto è possibile cliccare il pulsante Carica, presente in alto a sinistra, e scegliere il file da importare dal proprio computer.
Il caricamento è veloce e al termine dell’operazione il file viene mostrato nella lista di quelli disponibili su Google Drive.
Bisogna quindi cliccarlo per aprire il documento.
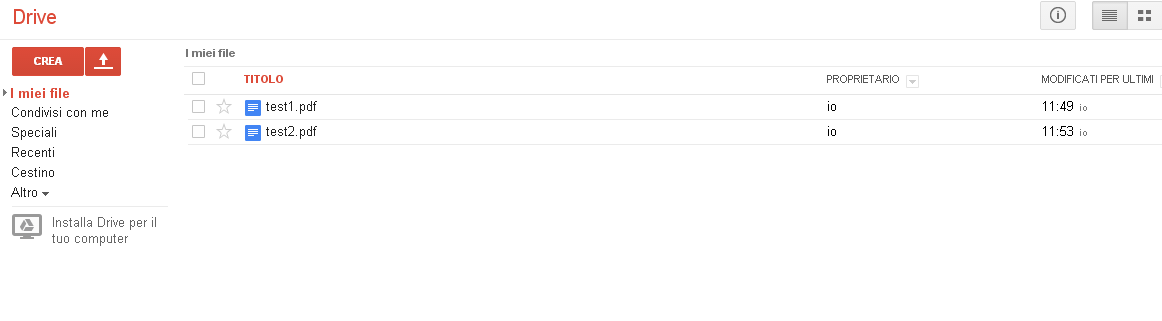
Il documento viene mostrato in modo che dopo ogni pagina dell’originale è presente una pagina con il testo estratto.
Utilizzando il menu File è poi possibile scaricare il file come documento Word o documento Txt, in modo da avere il testo a disposizione.
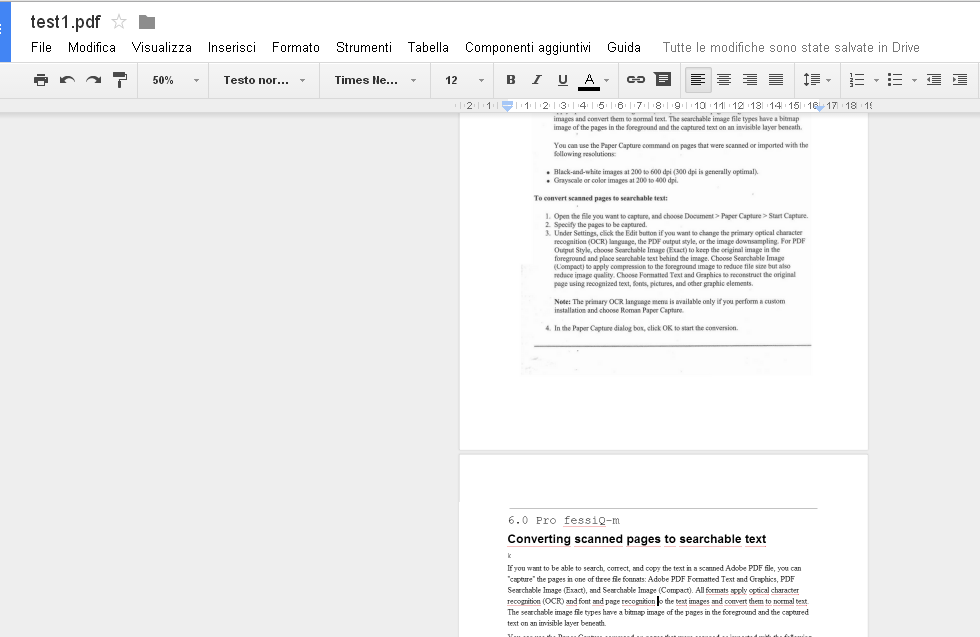
La formattazione viene mantenuta piuttosto bene, sono supportati i PDF e i principali formati di immagini e un numero elevato di lingue, tra cui l’italiano.
Sono presenti anche alcuni limiti, non possono essere elaborati file con una dimensione maggiore di dieci Mb e, nei documenti composti da più pagine, il testo viene estratto solo nelle prime dieci.
Free-online-ocr.com offre un servizio OCR online interessante.
Il funzionamento è piuttosto semplice, bisogna accedere al sito, caricare il file PDF o l’immagine da cui estrarre il testo, scegliere il formato che si vuole ottenere, tra Doc, Rtf, Txt e Pdf, e cliccare il pulsante Convert.
Una volta completata l’operazione, all’interno della pagina viene mostrato il link per scaricare il file con il testo riconosciuto.
Il riconoscimento OCR è sicuramente più lento di quello del servizio segnalato in precedenza, in questo caso non è però necessario fare la registrazione e non sono presenti limiti per quanto riguarda la dimensione dei documenti caricati.
Tra le funzionalità segnaliamo il supporto per le immagini con bassa risoluzione e la rotazione automatica delle pagine.
Secondo quando indicato sul sito, lo strumento supporta solo il dizionario inglese. Nei miei test sono però riuscito a estrarre testo da documenti in italiano senza grandi problemi e con una qualità piuttosto buona.
 Free-ocr.com, a differenza del sito segnalato in precedenza, supporta numerose lingue, tra cui anche l’italiano.
Free-ocr.com, a differenza del sito segnalato in precedenza, supporta numerose lingue, tra cui anche l’italiano.
Il servizio è gratis e non richiede la registrazione.
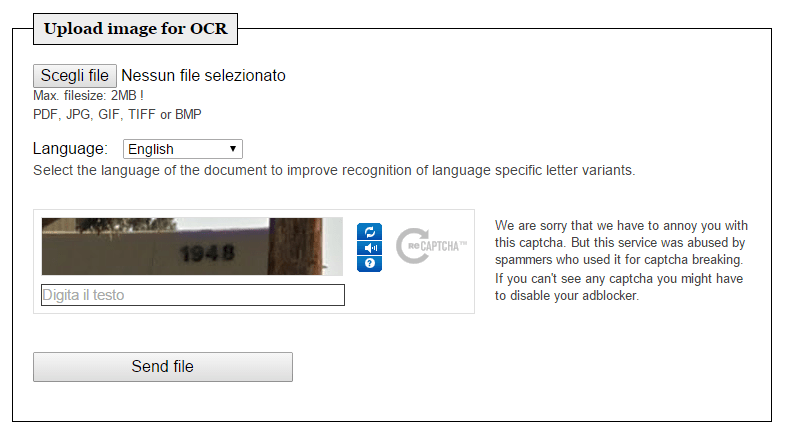
L’utilizzo, anche in questo caso, è molto semplice. Bisogna accedere al sito con il browser, cliccare il pulsante Scegli file e caricare il PDF o l’immagine in formato Jpg, Gif, Tff o Bmp da cui estrarre il testo, selezionare la lingua del documento e cliccare il pulsante Send file.
La conversione viene eseguita in modo piuttosto veloce e, al termine, viene aperta una nuova pagina in cui è presente il testo riconosciuto.
Nei nostri test i risultati sono stati buoni, è presente qualche errore nel testo estratto ma nel complesso l’operazione viene eseguita in modo corretto con i file in italiano e anche con immagini che non hanno qualità troppo elevata.
Il servizio ha alcuni limiti, non è possibile caricare infatti file con dimensione superiore a 2MB, viene convertita solo la prima pagina dei documenti PDF e non viene mantenuta la formattazione.
 I2OCR è un’altra soluzione interessante per chi vuole convertire il contenuto delle immagini in testo online.
I2OCR è un’altra soluzione interessante per chi vuole convertire il contenuto delle immagini in testo online.
Si tratta di un servizio gratis che non richiede la registrazione e che supporta numerose lingue, tra le quali anche l’italiano.
Il sito è in inglese ma l’utilizzo non è complesso, bisogna accedere con il browser e selezionare il file da caricare.
Il file da cui estrarre il testo può essere caricato dal computer o specificando l’indirizzo a cui si trova, sono supportati i formati Jpg, Png, Bmp e Tif, ma non i Pdf.
Bisogna poi impostare la lingua del documento e cliccare il pulsante Extract Test.
L’operazione viene eseguita in modo piuttosto veloce e, una volta completata, è possibile fare un confronto diretto tra il testo estratto e l’immagine.
Tra le caratteristiche segnaliamo la capacità di convertire in modo corretto il testo formattato su più colonne e il fatto che non sono presenti limiti relativi alla dimensione dei file.
Come detto in precedenza, non sono supportati i file PDF e la formattazione del testo viene persa.
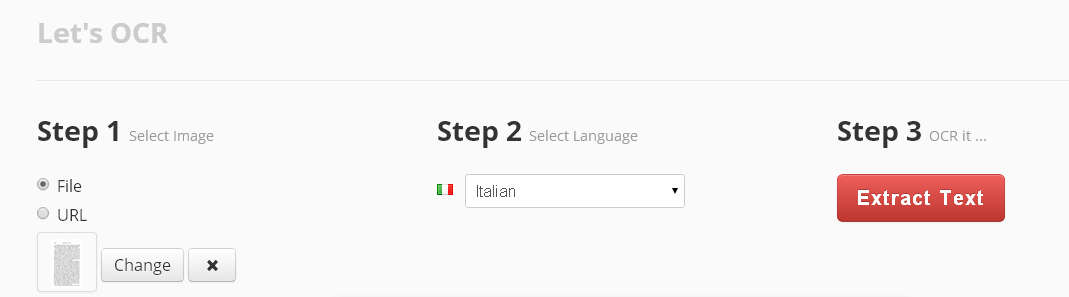 MyFreeOcr è un altro servizio online gratis.
MyFreeOcr è un altro servizio online gratis.
Il funzionamento è simile a quello degli strumenti segnalati in precedenza, bisogna accedere al sito con il browser, caricare il file PDF o l’immagine da cui estrarre il testo, scegliere la lingua e specificare il formato che si vuole ottenere.
Tra le lingue supportate troviamo anche l’italiano mentre come formato è possibile scegliere tra testo, Pdf e Word.
Nei miei test la conversione è risultata piuttosto lenta e la qualità inferiore a quella ottenuta con altri servizi di questo tipo.
Da segnalare poi che in alcuni casi non è stato possibile completare l’operazione a causa della comparsa di messaggi di errore sul sito.
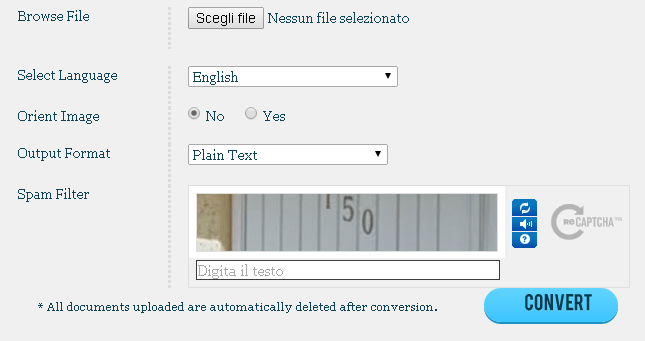
OcrOnline.com richiede la registrazione e presenta, nella versione gratis, diversi limiti.
Risulta essere infatti possibile caricare un massimo di cinque pagine alla settimana, con una dimensione totale che non può superare 10MB.
Per chi non deve fare il riconoscimento OCR del testo presente in PDF e immagini troppo spesso, rappresenta comunque una soluzione interessante.
Una volta effettuato l’accesso, è possibile caricare un file dal proprio computer, i formati supportati sono PDF, JPG, TIFF, PNG e GIF, impostare la lingua del testo contenuto nel file caricato e scegliere il formato che si vuole ottenere.
Il sito permette infatti di estrarre il testo e archiviarlo in file Doc, Pdf, Rtf e Txt.
La conversione viene eseguita in modo piuttosto veloce e al termine dell’operazione è possibile scaricare il file nel formato scelto.
Scegliendo Doc come formato, la formattazione del testo viene mantenuta in modo preciso. Inoltre la qualità del riconoscimento del testo è molto buona.

OnlineOcr.com può invece essere utilizzato sia con la registrazione gratis che senza.
L’utilizzo senza registrazione ha qualche limite in più, è possibile elaborare un massimo di quindici immagini ogni ora e la dimensione massima dei file è di 5 Mb, non sono inoltre supportati i PDF.
La procedura da seguire non è molto diversa da quelle che abbiamo spiegato in precedenza, bisogna accedere al sito, caricare le immagini che contengono il testo, scegliere la lingua e impostare il formato di output.
Il servizio permette di estrarre il testo e salvarlo in file Word, Excel e Txt.
Nel caso di conversione in Word, la formattazione viene mantenuta in modo preciso, comprese le parole in maiuscolo e in corsivo.

Programmi OCR
Cuneiform OpenOCR è un software OCR gratis disponibile per Windows.
Non supporta i PDF ma permette di convertire in testo tutti i principali formati di immagini.
Le lingue supportate sono numerose, troviamo anche il dizionario italiano, e i formati di output sono Txt, Rtf, Html, Word e Excel.
Tra le funzionalità segnaliamo poi l’acquisizione da scanner e la possibilità di elaborare più file contemporaneamente.
L’interfaccia non è sicuramente moderna, l’utilizzo è però semplice. Come prima cosa bisogna accedere al menu File – General Settings e impostare la lingua del testo presente nell’immagine nella scheda Markup and recognition.
In General settings troviamo altre opzioni interessanti come quelle relative al modo in cui deve essere gestita la formattazione.
Una volta completata la configurazione è possibile accedere al menu File – Open, importare l’immagine da convertire, e cliccare sul pulsante Recognition per avviare l’operazione.
Il riconoscimento OCR viene eseguito in modo veloce ma, nei miei test, la qualità non è stata troppo elevata. Ho infatti trovato diversi errori nel testo estratto e problemi nel mantenere la formattazione.
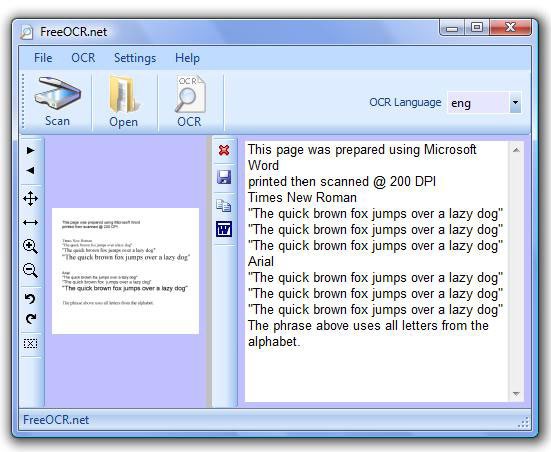
FreeOCR è un programma gratis che utilizza il motore OCR Tesseract, sviluppato in origine da HP.
L’applicazione supporta come input i file PDF e le immagini in formato TIFF, anche in questo è possibile l’acquisizione diretta da scanner.
Limitate sono invece le opzioni relative al formato di output, il testo può essere salvato sono come file TXT.
Tra i dizionari utilizzati per il riconoscimento del testo troviamo anche quello italiano, la qualità è buona, il testo viene infatti interpretato in modo piuttosto corretto.
Il limite è da individuare nel fatto che, visto che è supportato solo TXT come output, non viene mantenuta la formattazione.
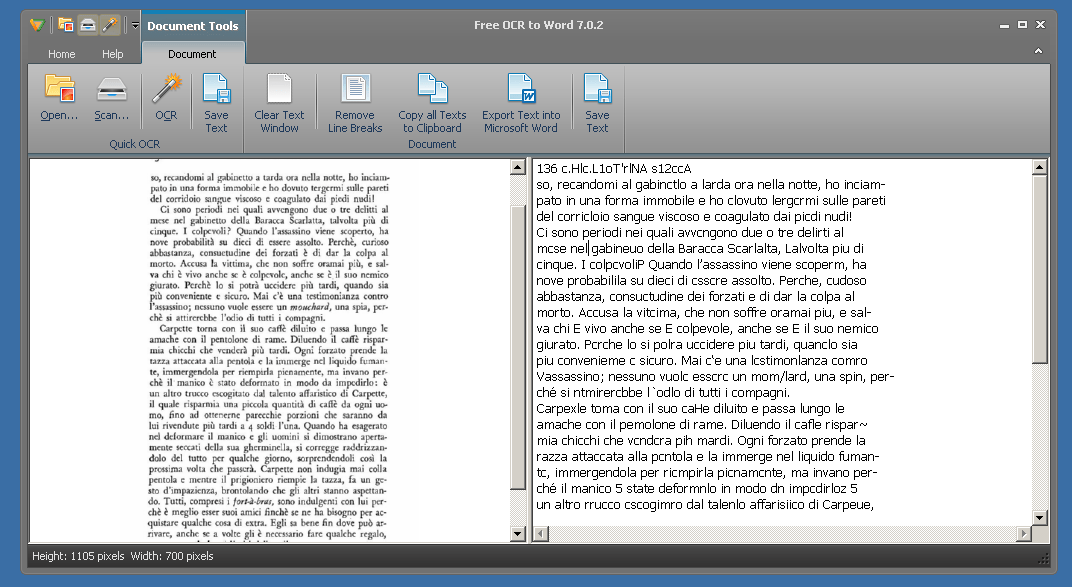
Free OCR to Word è un programma per il riconoscimento del testo disponibile gratis per Windows.
L’applicazione permette di elaborare le immagini acquisite dallo scanner e supporta i formati Jpg, Jpeg, Psd, Png, Gif, Tiff e Bmp.
L’utilizzo è molto semplice, basta avviare il programma, cliccare il pulsante open, importare le immagini e cliccare il pulsante OCR.
L’operazione viene completata in modo veloce e il testo viene mostrato nella finestra.
Bisogna però dire che sono presenti diversi limiti, non è possibile impostare la lingua del testo, non sono supportati i file PDF e non viene mantenuta la formattazione.
Il fatto che sia solo presente il dizionario inglese ha come conseguenza una qualità piuttosto bassa del testo estratto quando questo è in italiano.
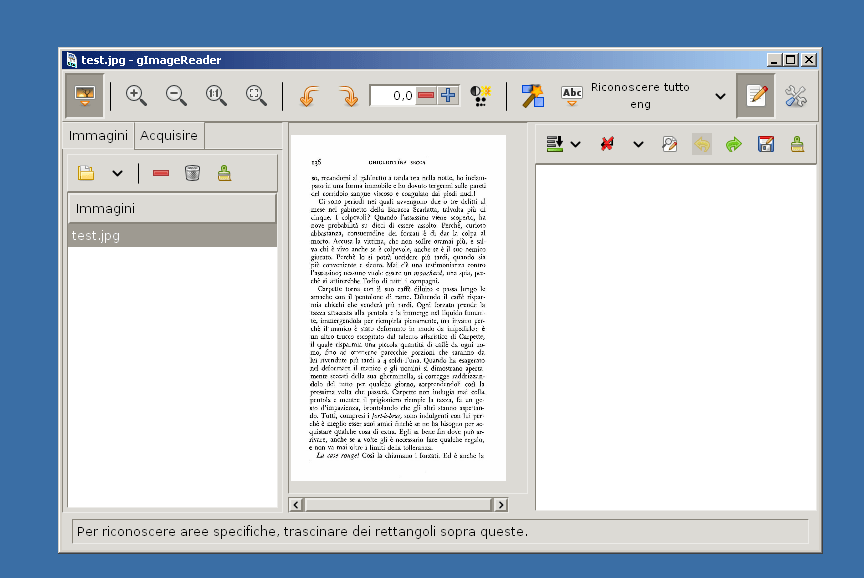
GImageReader è disponibile per Windows e Linux e si tratta di un’interfaccia grafica per il motore OCR Tesseract.
Supporta l’acquisizione da scanner e il riconoscimento OCR di PDF e immagini in formato JPG, GIF, PNG e TIFF.
L’utilizzo è più complicato rispetto a quello degli strumenti segnalati in precedenza, il programma utilizza infatti i dizionari di OpenOffice e per avere l’italiano è necessario scaricarlo tramite questo link.
L’interfaccia non è particolarmente curata ma l’operazione viene eseguita in modo piuttosto veloce.
La qualità del testo riconosciuto è buona, non viene però mantenuta la formattazione visto che l’unico formato di output supportato è TXT.
 SimpleOCR è disponibile per Windows e risulta essere gratis.
SimpleOCR è disponibile per Windows e risulta essere gratis.
Supporta i formati JPG, TIFF e BMP come input e i formati DOC e TXT come output.
Interessante la possibilità di eseguire il riconoscimento OCR del testo scritto a mano, la funzionalità può essere però utilizzata solo quattordici giorni.
I limiti del programma sono il mancato supporto al formato PDF come input, il fatto che non venga mantenuta la formattazione e il numero limitato di dizionari, non è infatti presente quello italiano.

Conclusioni
Il riconoscimento OCR non è mai perfetto, qualche errore è sempre presente nel testo che viene estratto dalle immagini.
Il livello di accuratezza degli strumenti che abbiamo segnalato, in alcuni casi, raggiunge però livelli molto alti.
Nei miei test i risultati migliori sono stati ottenuti con gli strumenti online, servizi come OcrOnline.com permettono di estrarre il testo da immagini e PDF con un numero limitato di errori e mantenendo la formattazione.
Per concludere ricordo che se si ha la necessità di convertire un normale documento PDF, che contiene testo che può essere selezionato e copiato, in un formato diverso non è necessario utilizzare i programmi e i servizi online OCR.
L’operazione può essere eseguita in modo più semplice tramite uno degli strumenti per convertire PDF in Word segnalati in un altro articolo.